Claude Code、そしてサグラダ・ファミリア
ClaudeCodeを本格的に使うようになって、日常のあらゆる業務が加速しているのを肌で感じる。タスクをこなす速さに自分自身で驚くし、やりたいことが次々と湧き出てきて、圧倒的に仕事が楽しい。
今、自分は完全に「変革期」あるいは「混沌期」にいる。仕事のやり方が不可逆なレベルで変化してしまった。
そんな加速の渦中で、ふと思い出したニュースがある。サグラダ・ファミリアの主塔が、ついに完成するという話だ。
Gaudí made the inside of the Sagrada Família magnificent without using any complementary elements, only architecture and light. pic.twitter.com/51FBTQI6jB
— La Sagrada Família (@sagradafamilia) 2026年2月26日
実を言うと、サグラダ・ファミリアは2017年に訪れたことがある。夏に行ったのだけれど、眩しい太陽の逆光に照らされた巨大建築物は有機物のようで圧倒されたのをよく覚えている。
そのときから完成に300年はかかるとされ、22世紀になることが確実視されていた建築が今年ほぼ完成してしまう。その最大の理由はイノベーションだという。 ガウディの設計図を3Dモデルで復元し、石の切削はコンピュータ制御。3Dプリンターによる試作。こうした技術介入によって、かつて10年を要した工程が、わずか1年にまで短縮されたらしい。
ClaudeCodeを叩きながら、この話をぼんやりと考えていた。 建築業界でこのイノベーションが起きたときも、現場は大騒ぎだったのかもしれない。ただ自分の視界に入っていなかっただけで。
結局、人は自分の身に降りかかった瞬間に初めて「世界が変わった」と騒ぎ出すのだなぁ。普段見ている世界がいかに狭いか痛感する。
自分が知らないだけで世の中は今あらゆる分野で爆発的に加速しているのだろう。 2026年。面白く、とんでもない未来に足を踏み入れてしまったんだな。
2025年 北欧旅行総括と知見メモ

旅行の概要
- 2025年は北欧3カ国を歴訪した。8泊9日。
- 完全個人旅行
旅行予約について
- 航空券は出発8日前に取得。今まででいちばんギリギリ
- その他、ホテルや国間移動のバスや列車は出発3~4日前にまとめて取った
- 相当ギリギリ
- 航空券はいつも通りskyscanner
- コペンハーゲン、ストックホルムはhotels.com、オスロはAirbnbの民泊を取った
今までの個人旅行の予約日の比較。今回がかなりギリギリなことがわかる。取れはしたけれどもっと早く取ったほうが安かったかも?

生成AI大活躍
- 今回場所選定から日によっての動き方までAI(Gemini)に相談しながらやった
- 「8泊9日で北欧3カ国を歴訪するならどのようなスケジュールにすればよい?」で国と都市とスケジュールを大まかに絞る
- 飛行機の時刻、予約したホテルと鉄道、バスの時刻を伝えて詳細なスケジュールを立ててもらう
- 土日は空いている時間が短い施設なども考慮した観光先を出力してくれる
- 希望を伝えると都度修正してくれる(コペンハーゲンではチボリ公園で遊ぶ時間を長くとりたい、など)
- 割と余裕のあるスケジュールを組むので前倒しして動くこともけっこうできる

- 旅先でわからないものを撮影してこれは何?と伝えるとめっちゃ詳しく教えてくれる

これは何
esim助かる
- 出国前にholaflyという海外で使えるesimを契約した。自分が契約した区間だとデータ使い放題で5000円ほど。
- これがめちゃくちゃ体験が良かった。出国前にesimをアクティベートして現地着いたらONにするだけ。
- 特に途切れるなど不満はなく、国をまたいでもローミングし直してくれる。
- 海外で他の日本人の方で他のesimサービスを使っている方はうまくアクティベートできていなかったので、holaflyは安定して使えたので他人に勧められる。 Buy eSIM for International Travel | Holafly
細かいメモ
- 航空会社アプリでのモバイルチェックインがめちゃくちゃ便利
- 飛行機の座席は窓際がよいか通路側がよいか
- 今回行きは窓際、帰りは通路側を取って比較してみた
- 精神的には誰にも気にせずトイレへ行ける通路側の方がラクかも
- ただし窓際の人がトイレへ出るときに移動する必要があるのがデメリット
- つまりこうすると良い
- 寝ることを主体にする場合は窓側
- 起きておくことを主体にする場合は通路側
- 寝る主体か起きる主体かはいく先の時差ぼけ調整を基準に考えると良い
- 移動中のスマホ充電について
- 飛行機はUSB-Aしか端子がなかったためスマホの充電はモバイルバッテリー頼りだった。ただ特に困ったことはなかったし、今後はよりUSB-Cに統一されていくだろうから今後気をつける必要はなさそう。なお、長距離バスはUSB-Cとコンセント共についていて、長距離電車はコンセントのみついていた。
総額
- 今回8泊9日で71万円ほど。
- 歴代の個人旅行で過去最高額になった(これでも食費を控えるなどはしたが…)
- 他の北欧歴訪したブログを見ても取り立てて高いわけではない。つまり北欧自体が高い。
- ギリギリで航空券を取ったので(これが往復35万円した)、これが数ヶ月前に取れると安くできるかも…ただなかなかねー、難しい
総括
ものすごくいろいろな場所へ行ったので内容については省くけれども、天気に恵まれたし大きなトラブルもなくめちゃ良い旅行になった。毎年行ける値段ではないけれど。
きみもAWS LoadBalancer Controller芸人になろう
AWSのKubernetesのingressコントローラーとしてAWS LoadbBanacer Controllerがあります。 これ、使うとALBが自動で起動されて使うことができます。つまり、ALBの仕様に完全に依存する形のIngress Controllerです。
ALBは高機能な反面、ingressとして使うと少々クセがある感じがしたので覚え書きとしてまとめていきます。 仕様に制限があるのでその制限を回避する方法も載せていきます。
なお、現時点での最新版、v2.7での情報です。
1. リスナールールを「条件」「アクション」に分けてアノテーションで記載する
ALBにはリスナールールという仕組みがあり、AWS LoadBalancer Controllerではこの仕組みを制御できます。
Application Load Balancer のリスナールール - Elastic Load Balancing
リスナールールはアクセスを「条件」と「アクション」に分けて記述する機能です。
 AWS LoadBalancer Controllerを使うとIngressでこのリスナールールを表現することができます。
AWS LoadBalancer Controllerを使うとIngressでこのリスナールールを表現することができます。
条件
条件はalb.ingress.kubernetes.io/conditions.${conditions-name} で、ここにSourceIPやらリクエストメソッドはGETやらの条件をつけることができます。
アクション
アクションはalb.ingress.kubernetes.io/actions.${action-name}で、ここにリダイレクトするなり、特定のKuernetes のservice resourceに転送するなりのアクションをつけることができます。
これは実際におこなった設定なのですが「password変更のRESTful APIを塞ぎたい」場合、以下のようなアノテーションをingressに設定することになります。
alb.ingress.kubernetes.io/conditions.deny-password-login: >
[{"Field":"http-request-method", "httpRequestMethodConfig":{"Values":["POST"]}}]
alb.ingress.kubernetes.io/actions.deny-password-login: >
{"Type": "fixed-response", "fixedResponseConfig":{"statusCode":"403"}}
conditionでPOST、actionで403のレスポンスを返す、としています。conditionとactionで名前を合わせることで一対の設定となります。 これをingressのruleに設定します。以下のようにすれば、example.com/api/session に対して上記のアノテーションを設定することができます。
rules:
- host: example.com
http:
paths:
- backend:
service:
name: deny-password-login 👈annotationで設定した名前を指定する
port:
name: use-annotation
path: /api/session
pathType: Exact
2.「条件」の個数制限に注意する
ALBの仕様として、「条件」は5つまでしか設定できません。
Application Load Balancer のクォータ - Elastic Load Balancing
この個数を超えるとingressを設定してもALBには設定は反映されません。AWS LoadbBanacer Controllerのログにはエラーが出力されますが、Ingress ControllerのPodやIngressは見かけ上異常なく見えるので注意が必要です。
3. pathTypeの仕様に注意する
IngressではpathTypeによって完全一致か前方一致かを指定できます。
ImplementationSpecific(実装に特有): このパスタイプでは、パスとの一致はIngressClassに依存します。Ingressの実装はこれを独立したpathTypeと扱うことも、PrefixやExactと同一のパスタイプと扱うこともできます。Exact: 大文字小文字を区別して完全に一致するURLパスと一致します。Prefix:/で分割されたURLと前方一致で一致します。大文字小文字は区別され、パスの要素対要素で比較されます。パス要素は/で分割されたパスの中のラベルのリストを参照します。リクエストがパス p に一致するのは、Ingressのパス p がリクエストパス p と要素単位で前方一致する場合です。
簡単に言えばExactは完全一致、Prefixは前方一致で、AWS LoadbBanacer Controllerを使った場合でもその仕様は変わりません。
ただし、pathTypeはALBの「条件」に設定されるため、前述の個数制限は留意する必要があります。
たとえば、先ほど出した例は Exactを使いましたが、
rules:
- host: example.com
http:
paths:
- backend:
service:
name: deny-password-login
port:
name: use-annotation
path: /api/session
pathType: Exact 👈これね
この場合は自動的に2つ「条件」を使うことになります。
- HTTPホストヘッダーが
example.com - パスパターンが
/api/session
そのため、他の条件(リクエストメソッドやソースIPなど)は3つつけることができます。
さて、Prefixはどうなるのでしょう?
rules:
- host: example.com
http:
paths:
- backend:
service:
name: deny-password-login
port:
name: use-annotation
path: /api/session
pathType: Prefix
この場合は3つ「条件」を使います。
- HTTPホストヘッダーが
example.com - パスパターンが
/api/session - パスパターンが
/api/session/*
そのため、他の条件(リクエストメソッドやソースIPなど)は2つになります。
いちばんわかりにくいImplementationSpecificの場合はどうなるのでしょうか?
これは指定したそのままがALBに設定されます。
path: /api/session
pathType: ImplementationSpecific
↑たとえばこの場合はExactと同じように、2つ「条件」を使うことになります。example.com/api/session には適用されますが example.com/api/session/hoge には適用されない設定です。
path: /api/session/*
pathType: ImplementationSpecific
これはExactでもPrefixでもない指定になって、2つ「条件」を使うことになります。 example.com/api/session には適用されず、example.com/api/session/hoge には適用されます。
こういう感じなので、AWS LoadbBanacer Controller を使う場合は設定が思った通りに反映されているかALBを確認しながらやると良いです。
4. 制限は回避できる
ここまで条件の指定は5つまでしかない、ということを口すっぱく言ってきましたが、この仕様は回避することができます。 たとえばソースIPをたくさん条件に指定したい場合は以下のように複数アノテーションを作ればよいです。
alb.ingress.kubernetes.io/actions.allow-from-certain-ips1: >
{"Type": "forward", "ForwardConfig": {"TargetGroups": [{"ServiceName": "exampleservice", "ServicePort": "80"}]}}
alb.ingress.kubernetes.io/conditions.allow-from-certain-ips1: >
[{"Field":"source-ip", "sourceIpConfig": {"values":["8.8.4.0/24", "8.8.8.0/24", "8.34.208.0/20"]}}]
alb.ingress.kubernetes.io/actions.allow-from-certain-ips2: >
{"Type": "forward", "ForwardConfig": {"TargetGroups": [{"ServiceName": "exampleservice", "ServicePort": "80"}]}}
alb.ingress.kubernetes.io/conditions.allow-from-certain-ips2: >
[{"Field":"source-ip", "sourceIpConfig": {"values":["8.35.192.0/20", "23.236.48.0/20", "23.251.128.0/19"]}}]
- host: example.jp
http:
paths:
- backend:
service:
name: allow-from-certain-ips1
port:
name: use-annotation
path: /example/*
pathType: ImplementationSpecific
- host: example.jp
http:
paths:
- backend:
service:
name: allow-from-certain-ips2
port:
name: use-annotation
path: /example/*
pathType: ImplementationSpecific
これは特定のソースIPからexample.jp/example/*にアクセスした場合はそのままexampleserviceに通すことを意味しています。
どうでしょう?AWS LoadBalancer Controllerの深淵を少しは覗くことができたでしょうか??
なんだか難しそうには見えますが、慣れてしまうと割と高機能なALBの機能を活用できるので便利です。
誰か困っている人に届きますように……
2023年ふりかえり
今年を雑に振り返りたい
今年、業務面を振り返ると自律して動けるようになって信頼を積み上げることができたという感じ。去年まではなんだかんだ「人の歩いてきた道」をなぞるところもあったと思うが今年は自社内の課題を見出しそれに対して解決していく動きが強くできたと思う。反面ちょっと技術力でなんとかする、みたいな動きにはちょっと乏しかったかもしれない。
組織やチームがダイナミックに変わった年でもあった。退職した人もいるし新しく入った人もいるし、今まであまり話さなかった人とも話すようになった。社内にいながら変化を感じられるのは刺激になるしとても良い。あと6年経つとチーム内でもだいぶ古株になってきているところにちょっと戸惑いがある。でもそれも信頼を積み上げてこられた証拠なのかもしれない。
あまり年の初めに抱負を立てることはないのだけれど、来年はもうちょっと技術力で〜した、という場面が増えると良い。登壇する機会も増やせたらな
今年も良い方々に恵まれました。来年もよろしくお願いいたします。
Herokuのデータベースを(Kubernetes Podを経由して)Amazon Auroraにデータ移行してみた
この記事はGMOペパボエンジニア Advent Calendar 2023の10日目になります🎄
最近PaaSであるHerokuにあるサービスをAWS(Amazon EKS on Fargate)で動かそうとしています。まだ検証段階ではあるものの、動作するところまではこぎつけました。HerokuとAWSを以下の組み合わせで移設しようとしています。
- Heroku Dynos → Amazon EKS
- Heroku Postgres(Add-on) → Amazon Aurora PostgreSQL
- Redis Cloud(Add-on) → Amazon ElastiCache for Redis
どれもいざやってみるとさほど困難さはなかったのですが(最初にEKSを構築してIngressを動かすほうがよほど手間がかかった)、Herokuで採用しているデータベースであるPostgreSQLに関しては知識ゼロから始めたもので学びが多かったのでやったことを書いていきます。雰囲気だけでも感じていただけたら嬉しいです!
なお、移行して動いた、という段階なのでパフォーマンスがどうなったといった視点は今回はないです…ご了承ください。
Auroraの構築については省略します😃他にも解説記事はたくさんあるかと思いますので
下準備
Herokuでデータベースのバックアップを取得するためにはHerokuのコマンドを実行することになるのですが、内部的にPostgreSQLのCLIコマンド─psql─をKickするため、最初にpsqlコマンドを利用できるようにする必要があります。psqlコマンドを使うためには以下からHerokuに構築しているPostgreSQLのバージョンに合ったものをインストールします。

インストールが終わったら、psqlコマンドを使うためにパスを通してあげます。自分は雑にzshrcに以下を入れました。
% tail -3 ~/.zshrc
# psql PATH
export PATH=${PATH}:/Applications/Postgres.app/Contents/Versions/latest/bin
psqlコマンドが打てるようになったら準備完了です😎
% which psql /Applications/Postgres.app/Contents/Versions/latest/bin/psql
Heroku PostgreSQLのデータベースを覗いてみる
ではHerokuのPostgreSQLをちょこっと覗いてみましょう。ログインはheroku pg:psql です。オプションを指定しない場合はHerokuでサービスが参照しているデータベースの所有者ユーザーになります。
% heroku pg:psql --> Connecting to postgresql-example-98765 psql (13.13, server 13.12 (Ubuntu 13.12-1.pgdg20.04+1)) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off) Type "help" for help. heroku-database::DATABASE=>
PostgreSQLではメタコマンドと言って短いコマンドでデータベースの内容をわかりやすく出力してくれる仕組みがあります。データベース一覧とその所有者を表示する\lを打ってみます。
heroku-database::DATABASE=> \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
----------------+----------------+----------+-------------+-------------+--------------------------------------------------
ma72h7wq4Z4uhlk | bkreikhp6iwaly | UTF8 | en_US.UTF-8 | en_US.UTF-8 | bkreikhp6iwaly=CTc/bkreikhp6iwaly +
| | | | | internal_utility_u1jk56dcsvf7q8=c/bkreikhp6iwaly
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres
(4 rows)
※データベース名、ユーザー名は架空のものです
いちばん上に表示されているma72h7wq4Z4uhlkが実際に使用しているデータベース、つまり今回データ移行するものです。HerokuのPostgreSQLのデータベース名はランダム文字列なんですね。右隣に表示されているOwnerの名前もランダム文字列です。
このデータベース名は後ほど使うので控えておきます。
バックアップ(スナップショット)をとる
それではリストア元のデータベースのバックアップを取得します。一般的な話になるのですが、データベースのバックアップをバックアップは2種類に大別できまして、コールドバックアップとホットバックアップがあります。コールドバックアップはデータベースのソフトウェア(今回の場合はPostgreSQL)を停止させてデータのバックアップを取得するものですが、PaaSであるHerokuはコールドバックアップは想定していないようです。
そこでホットバックアップを取得するのですが、これはとても簡単で以下のコマンドを実行するだけです。
% heroku pg:backups:capture
これは内部的にはPostgreSQLのpg_dumpコマンドを実行し、先ほど確認したma72h7wq4Z4uhlkデータベースの論理バックアップを取得しています。バックアップファイルはHeroku内に保管されます。
コマンド実行後Webコンソールでみても取得されていることがわかります。

※今回の場合は2MBと極小のデータですが、20GB以上のデータだとタイムアウトする可能性があるからデータベースのブランチ(耳慣れない表現ですがデータベースの書き込みがないレプリカ)を作成することを推奨しています。
バックアップファイルを取得する
Herokuに格納されたバックアップデータをローカルPCにダウンロードします。出力ファイル名を指定しない場合はlatest.dumpという名前のファイルがダウンロードされます。
% heroku pg:backups:download Getting backup from ⬢... done, #1 Downloading latest.dump... ████████████████████████▏ 100% 00:00 1.94MB % ls -l latest.dump -rw-r--r-- 1 shibatch staff 2030927 11 29 19:04 latest.dump shibatch@PM-GMXJX5060K sandbox-eks % ls -lh latest.dump
リストア用のPodを立てる
今回、EKSとAuroraはサブネットを分けている構成にしています。
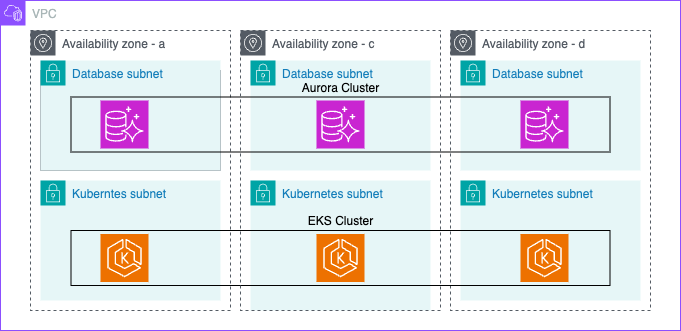
そこで疎通のテストも兼ねて、EKS上にAurora(PostgreSQL)をCLI操作するためのPodを立てて、そのPodにバックアップデータを転送してリストアすることにしました。 EKSに以下の通り、PostgreSQLが使えるPodを立てます。このコンテナイメージは内部でPostgreSQLを起動するためパスワードの環境変数指定が必要ですが、今回psqlコマンドを打ちたいだけなのでパスワードはなんでもよいです。
% kubectl run postgres-cli --image=postgres:13-alpine --env="POSTGRES_PASSWORD=test" % kubectl get pod NAME READY STATUS RESTARTS AGE postgres-cli 1/1 Running 0 2m49s
Podにリストアしたデータを転送する
KubernetesにはPodに対してファイルを転送するコマンドがあるので今回はそのコマンドで転送します(こんなコマンドあるの知らなかった)。 転送完了したらPodにログインしてファイルの存在確認します。
% kubectl cp ./latest.dump postgres-cli:/tmp/sandbox-pg.dump % k exec -it postgres-cli -- /bin/bash postgres-cli:/# ls -l /tmp total 1984 -rw-r--r-- 1 502 dialout 2030927 Nov 29 10:12 sandbox-pg.dump
カンのいい読者なら察したでしょうが、このコピーは検証用データベースの2MBのバックアップデータだからシュッとできたものの、本番用のGB単位のデータだったら転送に時間がかかる&Podのtmp領域の空き容量の関係でこんなうまくいかない可能性があります。この問題はこれから考えます😃
Auroraにデータベースのあれこれを作成する
あとはリストアしていくだけ…と言いたいところですが、Auroraにあらかじめリストアするデータベースを作成しておかないといけないようでした。 まずはログインしたPodを踏み台にしてAuroraのプライマリインスタンスにログインします。初回ログインではスーパーユーザーになるでしょう。下記ではデフォルトのpostgresユーザーとしています。
postgres-cli:/# psql --host=aurora-postgres.cluster-bkreikhp6iwaly.ap-northeast-1.rds.amazonaws.com --port=5432 --username=postgres --password -d postgres Password: psql (13.13, server 13.12) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off) Type "help" for help.
とにもかくにもHeroku PostgreSQLにあったデータベース名でデータベースを作ってみます。
postgres=> CREATE DATABASE ma72h7wq4Z4uhlk;
CREATE DATABASE
postgres=> \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
----------------+------------------+----------+-------------+-------------+---------------------------------------
ma72h7wq4Z4uhlk | bkreikhp6iwaly | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
<snip>
スーパーユーザーで運用するのはセキュリティ上望ましくないので、運用のためのロールとユーザーを作成します。
まずはroleから。今回はappというロール名にしました。
postgres=> CREATE ROLE app; CREATE ROLE
作成したapproleにデータベースへのアクセス権を付与していきます。
postgres=> GRANT CONNECT ON DATABASE ma72h7wq4Z4uhlk TO app; GRANT postgres=> GRANT ALL PRIVILEGES ON DATABASE ma72h7wq4Z4uhlk TO app; GRANT
ログインユーザーを作成します。今回はapp_userとしました。
postgres=> CREATE ROLE app_user LOGIN PASSWORD 'なにがし'; CREATE ROLE
app_userにapproleの権限を付与します。
postgres=> GRANT app TO app_user; GRANT ROLE
一旦postgresのコンソールを抜けて、ma72h7wq4Z4uhlk databaseへログインしなおします。
postgres-cli:/# psql --host=aurora-postgres.cluster-bkreikhp6iwaly.ap-northeast-1.rds.amazonaws.com --port=5432 --username=postgres --password -d ma72h7wq4Z4uhlk
app roleに対して、publicスキーマのテーブル、シーケンスに対する権限を付与します。
ma72h7wq4Z4uhlk=> GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO app; GRANT ma72h7wq4Z4uhlk=> GRANT ALL PRIVILEGES ON ALL SEQUENCES IN SCHEMA public TO app; GRANT ma72h7wq4Z4uhlk=> ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT ALL PRIVILEGES ON TABLES TO app; GRANT
リストアを実施する
Podログインした状態からバックアップファイルを指定してリストアします!リストア先は先ほど作成したデータベース名です。
postgres-test:/# pg_restore --verbose --clean --no-acl --no-owner -h aurora-postgres.cluster-bkreikhp6iwaly.ap-northeast-1.rds.amazonaws.com -U postgres -d ma72h7wq4Z4uhlk /tmp/sandbox-pg.dump <snip>
これでリストアは完了ですね!
この状態でPodのコンテナに設定するプライマリデータベース接続用の環境変数(Herokuからそのまま使う場合はDATABASE_URL)をAuroraのものに変更するとちゃんと接続してPodがRunningになってくれました。
DATABASE_URL: postgres://app_user:password@aurora-postgres.cluster-bkreikhp6iwaly.ap-northeast-1.rds.amazonaws.com:5432/ma72h7wq4Z4uhlk primary
今後の課題
というわけで、これでHeroku PostgreSQL→Auroraにデータ移行できたよ〜というものを紹介してみました。ここにある手順ですがまだ荒削りなところがあります。具体的には先ほど言及したもっと大きなサイズのデータ移行の場合どうするかということと、あと移行後のデータの完全性をちゃんと知りたいなぁと感じており、今後の課題です。
意外にすんなりできた、というのが感想です。本気でデータ移行する場合は書き込みできない状態にして実施することになるなどもっと細かい点を詰めなければなりませんが、何かしらの参考になれば幸いです😃
メンテナンスしやすいTerraformコードを書くために気をつけていること
TerraformというIaCのためのツールがあります。割とディレクトリ構成から管理の仕方までいろいろと自由がきくツールであります。
最近これでAWSのVPCやEKS、RDS、ElastiCacheをコードにしたのだけれど、個人的に今まで他の方が書いたコードを読み解いたりもしてきた経験から、なんとなく「こう書いた方が他人には優しいだろう」「将来的なメンテナンスコストが抑えられるだろう」と思いつつ書いていることに気づいたので、自分がどういうことに気を付けているかを書き留めてみます。 …といってもそんなに奇をてらったようなテクニックを使っているわけではないので(むしろそういうことをするとメンテナンスしにくくなるので🙅♀️)そんなの常識じゃん、みたいなこともありそうだけれどとりあえず書いてみます。
1. module化は避ける
いきなり好みが分かれそうですが、自分がTerraformでコードを書くときはmodule化しません。module化は便利ですがTerraformのコードの階層が深くなりがちで、その分何が生成されるのかが他人から見たときに直感的に把握しにくくなると感じています。共通化はworkspaceの使用、for_eachやforを使った利用に極力とどめておくべきです。
2.tfstateはなるべく小さく
tfstateを小さくすることは何個かメリットがあります。ひとつはterraform plan / applyの実行時間が短くなること。もうひとつは複数人で作業していても更新した箇所とは無関係な箇所でterraformの差分が現れてこれ何だろう〜で時間を食うようなこと(これが本当によくある…)が防げます。 どの程度の範囲で単位にするのが良さそうかというと例えばRDSだとそのRDSを使うためのIAMやSGまで、VPCだとSubnetとInternetGatewayとNatGatewayくらいまでくらいが妥当じゃないでしょうか。
3.workspace、for_eachの積極活用
環境を分けるときはworkspaceを使う、複数台作成するときはfor_eachを使う。これで大体の場合は対応できるというか、逆にこの方法でコードにできないような構成を避ける、環境の方をTerraformで管理しやすい方に寄せるまであります。
RDS(Aurora)を例にとると、
resource "aws_rds_cluster" "main_db" {
cluster_identifier = "main_db-${terraform.workspace}"
engine = "aurora-postgresql"
engine_version = var.main_db_engine_version
db_subnet_group_name = aws_db_subnet_group.main.name
vpc_security_group_ids = [aws_security_group.main_db.id]
db_cluster_parameter_group_name = aws_rds_cluster_parameter_group.main_db.name
}
resource "aws_rds_cluster_instance" "main_db" {
for_each = var.main_db_instances
identifier = "${each.key}-${each.value.az}"
cluster_identifier = aws_rds_cluster.main_db.id
instance_class = each.value.instance_class
engine = "aurora-postgresql"
availability_zone = each.value.az
promotion_tier = each.value.promotion_tier
}
このようにworkspaceでクラスタ名を分けつつfor_eachを使ってクラスタのインスタンスをそれぞれ設定できるようにします。 workspace(環境)によって分けるtfvarsは以下のようにします。
# staging
main_db_engine_version = "13.12"
main_db_instances = {
"user01" = {
az = "ap-northeast-1c"
instance_class = "db.t4g.medium"
promotion_tier = 0
}
}
# production
main_db_engine_version = "13.12"
main_db_instances = {
"user01" = {
az = "ap-northeast-1a"
instance_class = "db.r6g.xlarge"
promotion_tier = 0
}
"user02" = {
az = "ap-northeast-1c"
instance_class = "db.r6g.xlarge"
promotion_tier = 0
}
"user03" = {
az = "ap-northeast-1d"
instance_class = "db.r6g.xlarge"
promotion_tier = 0
}
"internal01" = {
az = "ap-northeast-1a"
instance_class = "db.r6g.large"
promotion_tier = 100 //writerの対象にしない
}
}
こうするとstagingはインスタンス1台だけ、productionは4台作って1台はフェイルオーバ対象から除外する… といったことが柔軟にできますね!1台だけインスタンスクラスを変える、といったこともできます。
4. 作成後にterraform importよりは構築時からTerraformで作成する
めんどくさくてWebコンソールから作成してからコードにしがちですが、構築時からTerraform使ったほうがよいと考えてます。Terraform ImportだとImport漏れが起こりがちで、コードから同じ環境がきちんと再現できるかが微妙に怪しいからです。せっかくコード化するならちゃんと運用時に使えるコードにしたいものです。
こんなところでしょうか?ほかにも無意識にやってることはありそうだけれども思いつく限りでこのあたりは気を付けて使ってます。TerraformのコツはやりたいことをTerraformに落とし込むよりTerraformコードにしやすい構成にすることだと思っております……ではでは
Datadogのログ管理機能のコストを削減する
Datadogにはログ管理という機能があり、ログを一挙に取得してそれを良い感じに判別する機能を持っています。 ただDatadogはAPMが優秀でよく使うのですが、その分ログ管理機能は(自分は)あまり使っていなく、その割に全ログ取得するとなるとかなりコストがかかっている状態でした。
そこでDatadogのログ監視は基本的には使わず、何か障害があったときに参考にする程度でよいかな、と思い、Agentが取得するログをerr / warn / crit とつくものだけに限定することにしました。 ドキュメントにも方法は載っているのですがAgent側でDD_LOGS_CONFIG_PROCESSING_RULESを使うとできます。
こんな感じ。
- name: DD_LOGS_CONFIG_PROCESSING_RULES
value: '[{"type":"include_at_match","name":"include_error_warn_critical_logs","pattern":"(?i)(err|warn|crit)"}]'
これで大文字小文字関係なくerr / warn / critとつくログのみを収集するようになります。 実際やってみると取得されるログが激減して良い感じ。

もともとのDatadogの思想とはそぐわないかもしれませんが、そんなこと言ったって無駄なログまで取得されて課金されていくのをみすみす見逃していくわけにはいかなかったのです。次の支払い明細が楽しみ。ではでは。